
| ☰ See All Chapters |
Anatomy of Kafka
Partitions are at the core of Kafka's architecture, influencing its storage, scalability, replication, and the flow of messages.
Partitions form the foundation of Kafka's design, impacting how data is stored, the system's ability to handle large volumes of data, data redundancy, and the movement of messages.
Mastering the concept of partitions is pivotal for a quicker grasp of Kafka's intricacies. This article provides an in-depth exploration of partition concepts, their structure, and their role in shaping Kafka's behavior.
Before delving into the specifics of partitions, it's essential to establish the foundational context. Let's examine some overarching concepts and explore their connections to partitions.
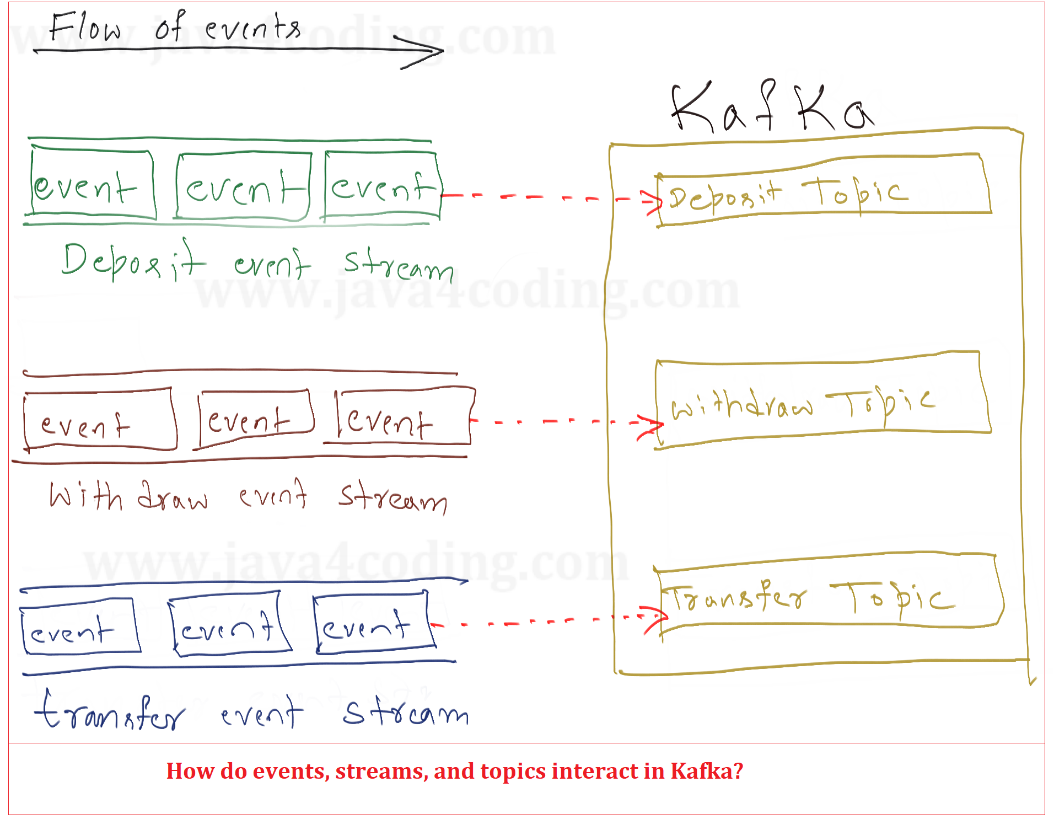
Events
An event embodies a historical occurrence or incident. Events possess an unchangeable nature and are in a constant state of movement. They invariably journey from one system to another, bearing the record of state alterations that transpired.
Streams
An event stream is a continuous flow of interconnected and related events that are dynamically moving and unfolding over time. This concept is fundamental in various fields, especially in the context of real-time data processing, event-driven architectures, and stream processing. Event streams enable the analysis, processing, and interpretation of data as it's generated, allowing for timely insights and actions.
Topics
When an event stream enters Kafka, it becomes persisted as a topic. Within Kafka's framework, a topic represents a materialized form of an event stream. Essentially, a topic serves as a resting place for a stream of events.
Topics serve the purpose of logically grouping related events and ensuring their durable storage. An apt comparison for a Kafka topic is a database table or a folder in a file system. This structural analogy helps convey the role and function of topics within the Kafka architecture.
Topics are a pivotal concept in Kafka, acting as a decoupling mechanism between producers and consumers. Consumers retrieve messages from Kafka topics, while producers publish messages into them. Importantly, a single topic can accommodate multiple producers and consumers, allowing for a highly flexible and scalable event processing setup.
Partitions
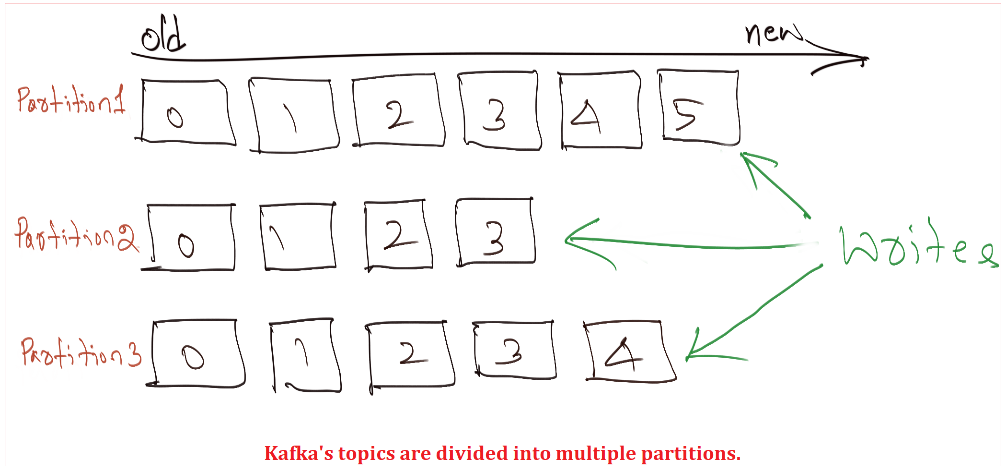
Kafka's topics are divided into multiple partitions. While a topic is a logical concept in Kafka, a partition represents the smallest storage unit that contains a subset of records owned by a topic. Each partition functions as a singular log file, with records being appended to it. When referring to the contents within a partition, the terms "event" and "message" can be used interchangeably.
Offsets and the ordering of messages
Each record within the partitions is assigned a sequential identifier known as the offset, which remains unique for every record within the respective partition. Managed by Kafka, the offset is an incremental and unchanging value. When a record is written to a partition, it is appended to the log's end, receiving the subsequent sequential offset. The illustration below depicts a topic comprising three partitions, with records being continuously appended to each partition's end. It's important to note that while the messages within a given partition maintain their order, messages across an entire topic do not guarantee a consistent order.
Kafka Brokers
A Kafka cluster consists of one or more servers referred to as Brokers within the Kafka ecosystem. Each broker is responsible for managing a portion of the records that collectively belong to the entire cluster. Kafka employs a strategy where it distributes partitions of a given topic across numerous brokers. This approach yields several advantages, which include:
Horizontal scalability: Placing all partitions of a topic on a single broker would restrict the scalability of that topic to the I/O throughput of the broker. This limitation means the size of the topic will always be constrained by the capabilities of the largest machine in the cluster. However, by distributing partitions across multiple brokers, a single topic can achieve horizontal scalability, unlocking performance levels well beyond what a single broker could provide.
Parallel Consumer: Enabling a single topic to be consumed by multiple consumers in parallel is facilitated by spreading partitions across multiple brokers. When all partitions reside on a single broker, the capacity to accommodate consumers is constrained. In contrast, distributing partitions across multiple brokers increases the potential for accommodating more consumers simultaneously.
Multiple Consumer Instance: The capability for multiple instances of the same consumer to connect to partitions situated on different brokers is a significant advantage. This setup allows for exceptionally high message processing throughput. Each consumer instance is assigned to a specific partition, ensuring that every record is managed by a distinct processing owner.
Replicas of partitions
Kafka maintains multiple copies of each partition across multiple brokers. These duplicated copies are referred to as replicas. In the event of a broker failure, Kafka retains the ability to continue serving consumers by utilizing the replicas of partitions that were owned by the failed broker. This redundancy ensures data availability and fault tolerance within the Kafka cluster.
All Chapters
