
| ☰ See All Chapters |
How to read records from kafka partitions
Kafka's messaging system works in terms of message consumption and offset management. Kafka's approach to message delivery and consumption is quite different from traditional publish/subscribe systems. In Kafka:
Push vs. Pull Model: Unlike some other messaging systems, where messages are pushed from the broker to consumers, Kafka operates on a pull model. Consumers actively request messages from Kafka brokers when they are ready to process them.
Partitioned Topics: Kafka topics are divided into partitions. Each partition is a linearly ordered, immutable sequence of messages. Partitions allow for parallelism and scalability since multiple consumers can read from different partitions concurrently.
Consumer Offsets: The offset is a unique identifier assigned to each message within a partition. It serves as a bookmark or cursor for consumers, indicating the position up to which they have consumed messages. Consumers keep track of the offset of the last consumed message for each partition they are subscribed to.
Consumer Responsibility: Kafka doesn't manage consumer offsets itself; it's the responsibility of the consumer to track and manage the offsets. This design choice gives consumers more control and flexibility over their consumption behavior.
Crash Recovery: As you mentioned, the ability to control offsets and the responsibility of consumers to manage them makes it possible to resume consumption from the point where it was left off, even after a crash or restart. This is particularly valuable for ensuring data consistency and fault tolerance.
At-Least-Once Delivery: Kafka provides an "at-least-once" delivery guarantee, meaning messages will be delivered to consumers at least once. If a consumer crashes after processing a message but before acknowledging it, Kafka can redeliver the message to ensure it's processed.
Kafka's design choices make it a powerful tool for building distributed, fault-tolerant, and scalable data processing systems. However, managing offsets and handling the complexities of consumer behavior are responsibilities that developers need to address when using Kafka. This design provides both flexibility and challenges, as developers have fine-grained control over message consumption but must also manage the intricacies of offset management and potential duplicate processing.
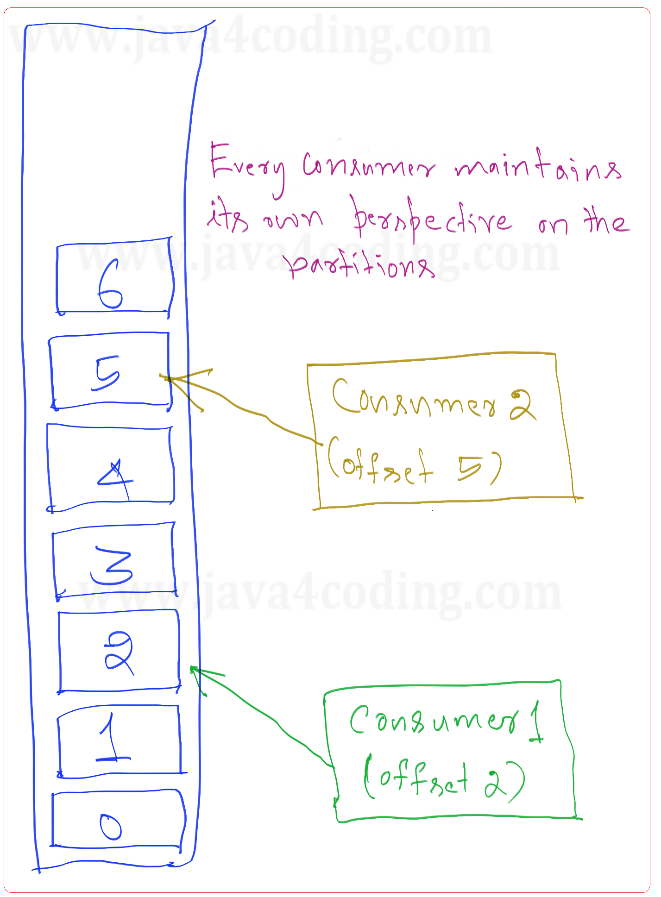
A partition can be consumed by one or multiple consumers, each reading from different offsets. Kafka introduces the notion of consumer groups, in which multiple consumers are united to consume a specific topic. Consumers sharing the same consumer group possess identical group-id values. The consumer group concept guarantees that a message is exclusively read by a solitary consumer within the group. As a consumer group consumes the partitions within a topic, Kafka ensures that each partition is exclusively consumed by a single consumer within the group. The diagram below illustrates this relationship.
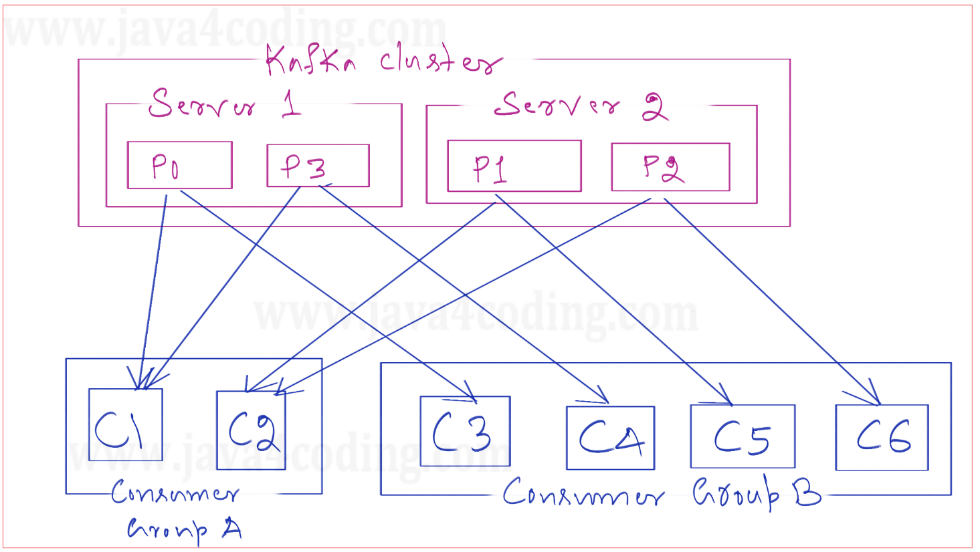
Consumer groups empower consumers to achieve high message processing rates through parallelization. However, the utmost level of parallelism a group can achieve aligns with the number of partitions present within the respective topic.
For instance, if a topic has N partitions and there are N + 1 consumers within a group, the initial N consumers will each be assigned a partition, while the remaining consumer will remain inactive. This situation persists unless one of the N consumers encounters a failure. In such a case, the standby consumer will then be assigned a partition, effectively implementing a responsive hot failover strategy.
The visual representation below provides an illustrative depiction of this scenario.
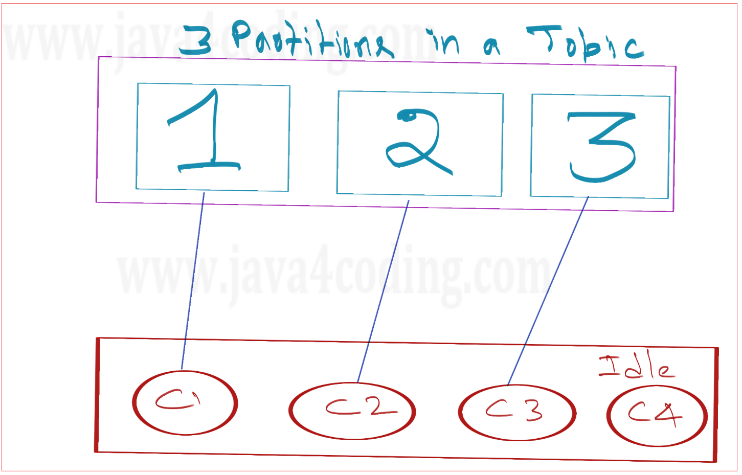
The crucial insight is that the quantity of consumers does not dictate the extent of parallelism for a topic. Rather, it is the count of partitions that determines the degree of parallel processing.
If you have less consumers than partitions, what happens?
Indeed, each consumer is a member of a consumer group. When Kafka dispatches data to a consumer group, all records from a partition are directed to a singular consumer within that group.
If there are more partitions than consumers within a group, certain consumers will handle data from multiple partitions. Conversely, if there are more consumers than partitions, some consumers might remain without data to process. The introduction of new consumer instances to the group leads to the distribution of partitions from existing members. Conversely, removing a consumer from the group or experiencing consumer failure triggers the reassignment of its partitions to other members.
To address your inquiries:
Consuming All Messages: Having fewer consumers than partitions doesn't inherently signify that not all messages on a topic will be consumed. Certain consumers within the same group can manage data from multiple partitions.
Monitoring Consumers: In a cloud environment, monitoring the number of running consumers and their association with topic partitions is managed by Kafka itself. The process of rebalancing occurs when new consumers join or existing ones exit the group, ensuring proper distribution of partitions among active consumers.
Kafka handles the intricacies of partition distribution and consumer coordination, enabling you to focus on designing your applications without having to manually manage these aspects.
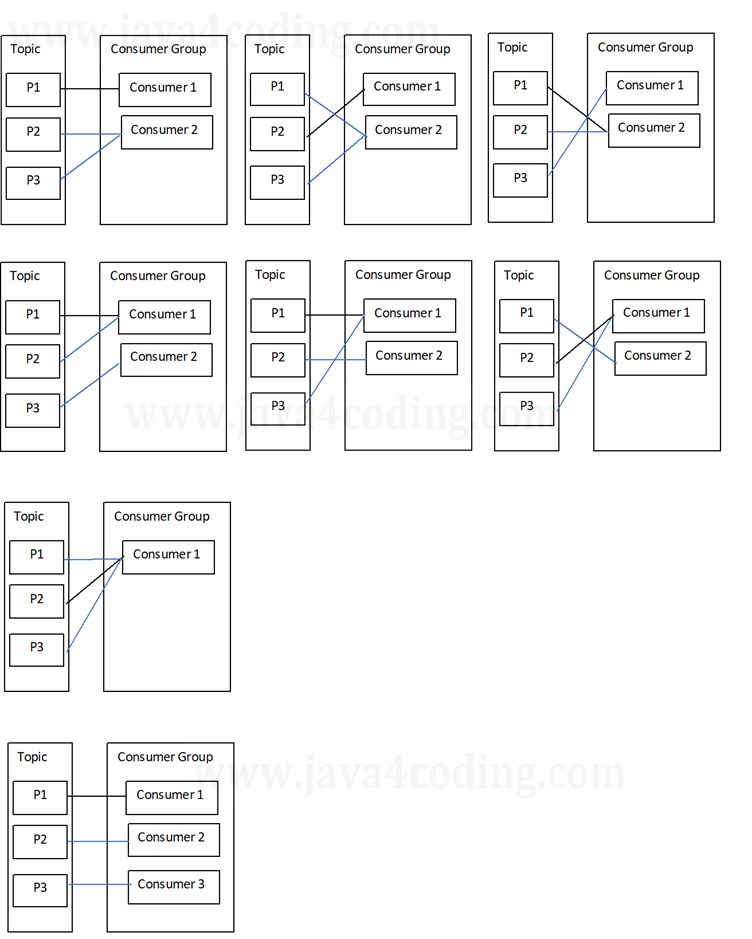
What if you have multiple consumers on a given topic#partition?
You are absolutely correct, and I appreciate the clarification. My apologies for any confusion caused by the previous responses. Here is the accurate explanation:
In Kafka, each partition within a topic can be consumed by only one consumer within a consumer group. However, if you have multiple consumer groups, the same partition can be consumed by one consumer from each consumer group.
The image you're referring to is likely demonstrating how consumers within a consumer group consume from partitions. Thank you for providing the accurate information and helping to clarify the concept.
All Chapters
